
2019 我的資料科學轉職歷程:對外如何定位自己

系列文列表
- 2019 我的資料科學轉職歷程:從迷惘出發的動機,以及為什麼不寫面試文
- 2019 我的資料科學轉職歷程:把自己當產品賣的探索
- 2019 我的資料科學轉職歷程:對外如何定位自己
- 2019 我的資料科學轉職歷程:對內形塑的價值觀
- 2019 我的資料科學轉職歷程:產業職缺觀察
專精的資料科學職缺 vs. 通用的軟體工程師
有些時候,我面試完得到的 offer 職稱,跟原本一樣是軟體工程師(Software Engineer),這並不是說我的工作就跟資料科學無關,反而是因為恰好都有相關,所以才無法歸類成其中一種。
至於哪一種路比較好,則是見仁見智。有時候興趣才能讓你精進,有時候廣泛接觸各種領域能讓你選擇更多,也有時候不夠專精會容易被特定領域的強者比下來。
為什麼自己的資料科學之路並不像其他人比較專精的資料科學家(Data Scientist)/資料工程師(Data Engineer)/資料分析師(Data Analyst)?我歸納出幾個原因:
資料科學領域還不成熟,特別是當經驗來自新創
除了極少數大企業的研究單位能夠鑽研純科學的技術之外,多數小公司資料科學的工作可能比工程團隊更接近業務端,結果就是會面對各種不確定性、解決很實際,卻不是純技術的問題。
而前幾年的台灣業界在資料科學發展還沒有很成熟,不管你是什麼職缺,實際上的工作很可能都不是職稱字面上的意思,在新創公司之中,更可能一人身兼多職,什麼都碰,當然也就會擔心自己不夠精通。
沒有限制自己的想像與發展
有些資料科學家喜歡研究理論,對於鑽研最新的論文與學術趨勢、如何應用在商業問題上非常有熱情,對於工程實務比較沒興趣;有些資料工程師則是對導入平台技術、研究服務如何擴展比較有熱情,對於商業邏輯就沒太多興趣。
也有一些人像我,既喜歡研究如何將資料科學應用在商業邏輯,也對於如何實現資料工程的工作很有興趣。所以當團隊需要做模型或討論演算法的時候,我可以參與、當團隊需要把產品落地的時候,背後的工程我也可以支援。
這是一把雙面刃,我的時間與精力有限,所以不可能同時精通兩邊。所以上面的敘述也可以反過來看:當團隊需要精通資料科學建模與理論研究的時候,我不會是最好的科學家;當團隊需要精通資料工程擴展性、導入最新框架、設計資料流系統的時候,我也不會是最好的工程師。
講到這裡,你應該可以稍微理解「定位」這件事情對於通才的重要性。
面試官(公司)的想像不同
每個人對資料科學的想像都不一樣,而每間公司的業務、需要的技術、部門負責的領域又非常的不同。
面試官可能只會注意到他最熟悉的關鍵字:廣告領域可能在意預測各種轉換模型的經驗、電商可能在意對人屬性的分析、資料工程可能注意到 ETL 資料流的經驗;更廣泛一點,也有可能參考一般軟體工程的經驗,或是專案管理的經驗。
因此,我自己可以應徵的職缺不只一種,而面試官也不見得會選到我最擅長的那一種,通常每個職缺之間都有重疊的地方,但也有可能我們認為的是很接近的角色,只是職稱不同罷了。
再者,很多新創公司通常只開出特定專精的職缺,但不代表他們不需要其他專業職缺跟通才。我就遇過原本只開後端工程師職缺,但內部討論後轉為面試資料工程師,也有資料工程師面試之後正式 offer 變成軟體工程師,或是應徵資料工程師變成 MLOps 的職缺。
所以有時候,找到有興趣而且你能發揮的公司,會比你只去應徵某個特定職缺來得有效益。而過程中如果遇到好的獵頭或 recruiter 幫你導向正確的職缺,也會讓你少走很多冤枉路。
通才要怎麼總結經驗
我知道自己有一些優點是專精角色所沒有的,但如果面試的時候沒有好好處理,說自己是通才,反而會讓人覺得是「鬆才」,所以我認為花一些時間在總結自己的經驗是必要的。
以下是我用的方法,其中並沒有什麼厲害的技巧,簡單來說大致分成「整理資訊」、「如何呈現」、「收集回饋並改進」幾個面向。
總結出脈絡,比起平舖直敘的流水帳經歷更好
你可能會想,跨領域的人才只要說自己是 T 型人就好了,的確,很多說法都強調 T 型人才的重要性,現實中也需要這樣的人,但「需要 T 型能力的角色很多,真正空缺出來的 T 型職缺並不多」。
換句話說,跨領域溝通是不可或缺的,但公司並不會有很多「跨領域溝通的專職角色」,因為這些技能可能隱性地存在於所有角色之中,而不是一個摸得到的職缺。
因此,面對還未合作過的對象,如何說服對方我是 T 型(藉由跨領域的經驗幫助專業的部份)而不是一型(樣樣通、樣樣鬆)的人;並且把這些看似很雜的經驗總結,就變得非常重要。
畫圖說故事:組織分工一目了然
以下這段是我面試初期介紹自己的說詞,建議先略過往下,有興趣再回來讀:
首先,我將自己經驗劃分成兩個階段簡述
我在目前公司的前兩年屬於 data science team,產品主要圍繞在數位廣告,從跟使用者討論業務需求、制定簡單spec、訓練模型、deploy model,上線之後分析成效與找出問題,簡單來說是一條龍負責。
這個階段比較多是 PoC 的快速迭代驗證,產品能存活遠比品質重要,但我得到很多產品面的經驗。
接著後半階段,有感於在 data science 遇到的各種火坑,必須要有人處理工程活,於是在上層(資料科學)與下層(通用資料基礎建設)中間,跟夥伴們一起建立了負責通用資料服務的「膠水」團隊。
接下來,我會解釋跨團隊、跨領域的重要性
多數人都知道資料科學家,可能也知道資料工程師,但這兩種角色性質剛好相反:前者解決問題的方式非常的專一且垂直、後者的作法則是傾向通用且水平。
如果是需求非常明確且固定的公司,或許能比較無痛地整合,但在一個高速成長且快速迭代需求、不確定性極高的團隊中,中間這一層跨領域的「橋樑」,有時候擔任「膠水」組合出確實能動的產品,或是變成「潤滑油」讓組織運作順暢的職責,就不可或缺。
這算是資料科學實務上很重要、卻也最常被忽略的一塊,在大公司中或許還有資源建立這樣的團隊,但小組織中則可能只是由一個資深成員、或其中一個 manager/lead 來分擔。
恰巧我經歷了公司從 30 人到 300 人的過程,在這之中不可避免地會需要處理很多這樣的事情。
最後補充其他 T 型的周邊經驗
這些東西未必是我的專精領域,但作為一個資料科學領域的工程師,做過、且願意做這些事情,會是一項有利的因素
專案管理與跨團隊協調也是很常需要做的事情,很常遇到兩邊能力都很強,但是做出來的東西沒有真正切合業務需求,或者是用錯方法事倍功半,其實只要簡單的解法就能滿足需求,都是因為溝通不良導致。
因為我看過各種錯誤,自己也犯了很多錯誤,所以或許能幫助公司在這些地方少走一些冤枉路。
這五年雖然是個蠻長的時間,但我做的事情一直有在跟著公司經歷不同階段的組織變化而改變,目標都是在幫助 AI 業務與產品成長。
除了工程師的工作之外,我偶爾也會接觸到專案管理,另外資料管理(data management)或資料治理(data governance)也是我有實務經驗的領域。
嘗試與改進
原本我嘗試用講的,經過一兩次面試之後,我發現光是總結、說故事還不夠,必須要快速、一目瞭然。
因此我開始嘗試畫圖,從時間與空間來切分我的經驗,並解釋為什麼我在不同的階段做出這些選擇、這些工作為什麼重要。
後來我大概可以在兩分鐘內,把上面整段落落長的文字,用三個關鍵字(兩階段、橋樑、T 型)解釋清楚。
這個是經過面試一陣子之後重新整理的圖,當然,面試的時候不會畫這麼仔細。
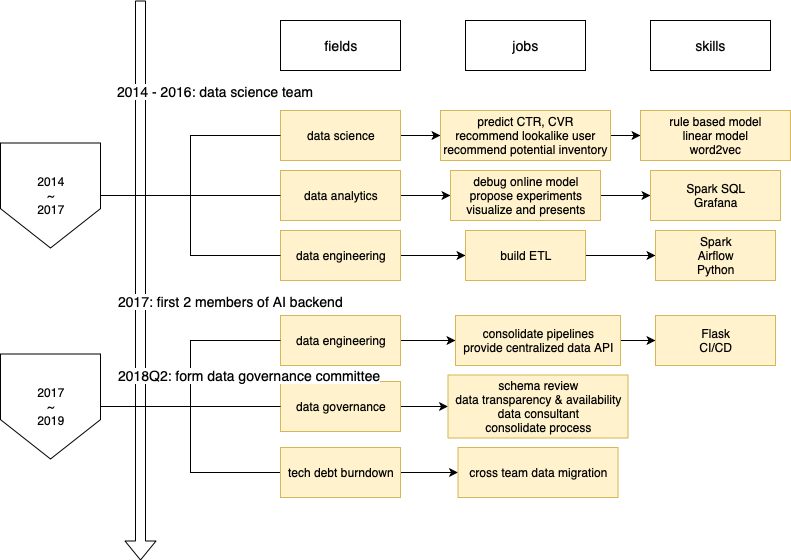
畫圖的好處是可以先畫出最粗略的時空關係,有需要的話再根據面試官的反應去細部講解,所以如果面試官有興趣,或者是他不熟悉的地方,就會根據情況補充。
用講的當然也可以準備簡單版跟完整版,但就比較難有這種階層關係,比如我講完簡單版,再講完整版的時候,面試官可能已經忘了對應到簡單版的哪個部分。
小結
能夠畫圖說明、跟面試官解釋得口沫橫飛,固然是好事;但說到底還是需要先對內探索並說服自己,才有辦法對外說服別人。這需要從自己的經驗總結、以及價值觀的累積而來,也是對我來說真正重要的課題。
下一篇我會試著進一步解釋這些較抽象的價值觀,希望看到本篇的結果之後會比較多人有興趣。