
資料科學角色光譜圖
原本上一篇應該就要結束了,但因為這篇《設計角色的光譜》The spectrum of design roles in 2018 - UX Collective 呈現的方式實在太棒了,忍不住也想來做一張資料科學版本的。
與那張設計角色光譜一樣要做個聲明:這張圖的目的是忠實呈現我個人在目前(2019)的認知,並非為了諷刺而作,如果對每個角色的細節有興趣,請參考上一篇 資料科學的職稱分類演進 - 科科寫寫 ,這裡不會做太多說明。
那麼開始了。
專注在單一功能的資料科學角色
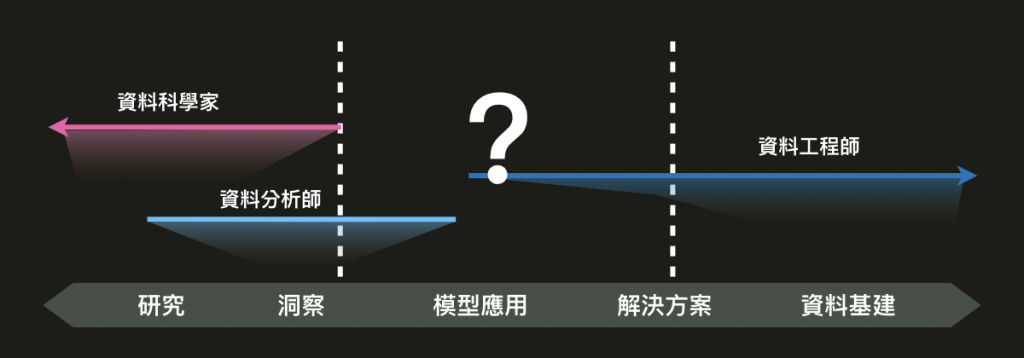
注意線條代表可能的廣度,而陰影部分則代表技術能力的深度。舉例來說資料工程師的專精領域在資料基礎建設,但根據不同公司的需求,部分資料工程師也會牽涉到線上的模型應用,以及整體的解決方案實作。
這張圖很明顯可以看到傳統的分法是不敷產品需求的,因為最重要的應用與解決方案只有很小一部分被涵蓋到,如果按照這種方式徵才,產品要落地就很困難。
過渡期
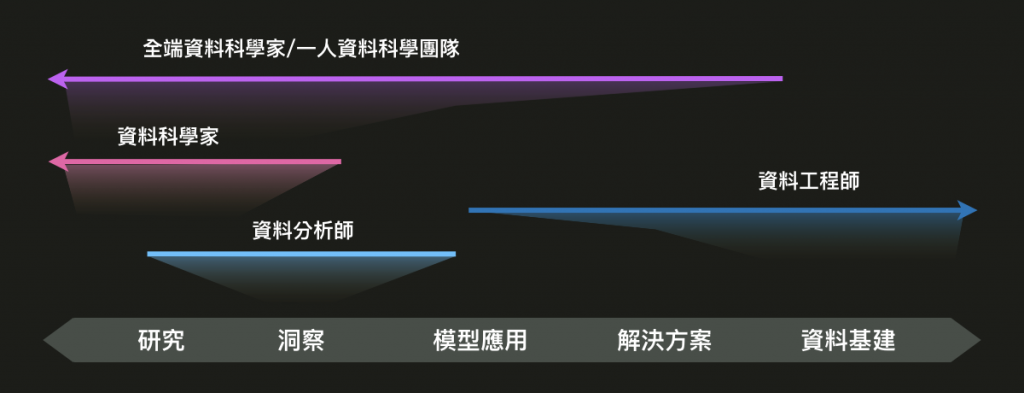
既然工程師與科學家中間的坑這麼大,那總要有人來填吧。
因為資料科學家很「性感」,想做 AI 研究的人太多,相對地資料工程師很難在學校就培養出來,再加上科學家又很容易被推上業務火線,種種原因導致台灣的生態中,最有可能全包的就是科學家了,
但這不是永遠的辦法,研究領域的科學家畢竟跟工程師還是有一段差距,早期 PoC 的階段或許能先擋砲火,等到業務要擴張的時候就會發現有很多營運問題出現。
部分科學家也並非軟體專長,而是數學、統計背景,要實作在產品上還需要其他軟體工程單位支援,要迭代產品的效率就會比較低,於是又有了下面幾個角色被提出來。
全光譜角色
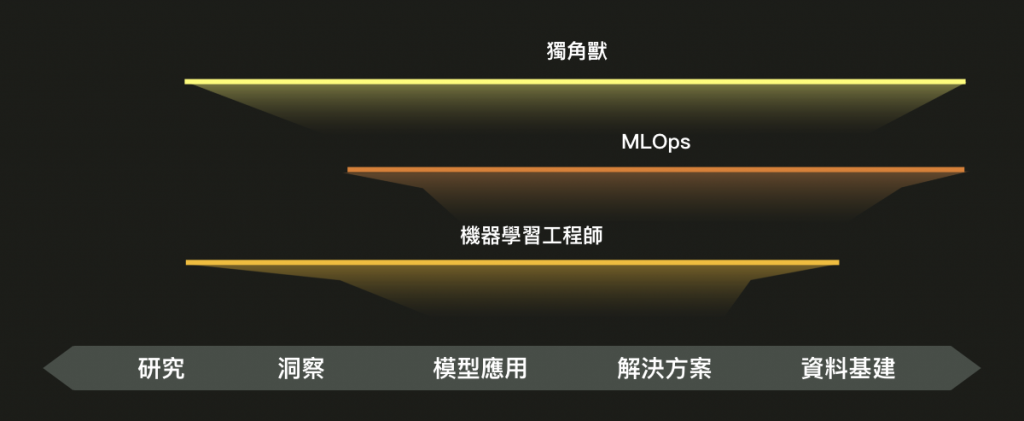
ML Engineer 與 MLOps 都是比較新的概念,其中 MLOps 又更新了一點,共通點是雖然「研究」與「工程」都不是最專精的,但都有部分的人可以做(或目前不得不做)
獨角獸這一個角色也是抄《設計角色光譜》來的,除了最深入的演算法研究以外,什麼都懂的工程師像是 DevOps/MLOps,這類綜合的人才在未來幾年內會是業界最需要的。
你可能會懷疑怎麼會有人什麼都懂,但我覺得還是有可能的。一是因為他並非「什麼都懂」,而是「只在資料科學領域的經驗豐富」。
二是回想求學過程,總是會有一些大神,理解能力比起前段的學生完全不是同個等級,這些人學東西非常快、能把一樣道理融會貫通到其他領域。
最後一個原因可以參考軟體工程的發展,現在的軟體工程師我們會期待他懂演算法、資料結構、實務要會實作後端伺服器、會使用資料庫,因為這些領域現在已經相對成熟了,或許以後這裡的「獨角獸」不會像現在太稀有,而是變成軟體工程師的其中一個面向而已。
全部放在一起
把上面的角色全部疊在一起看看長怎樣。
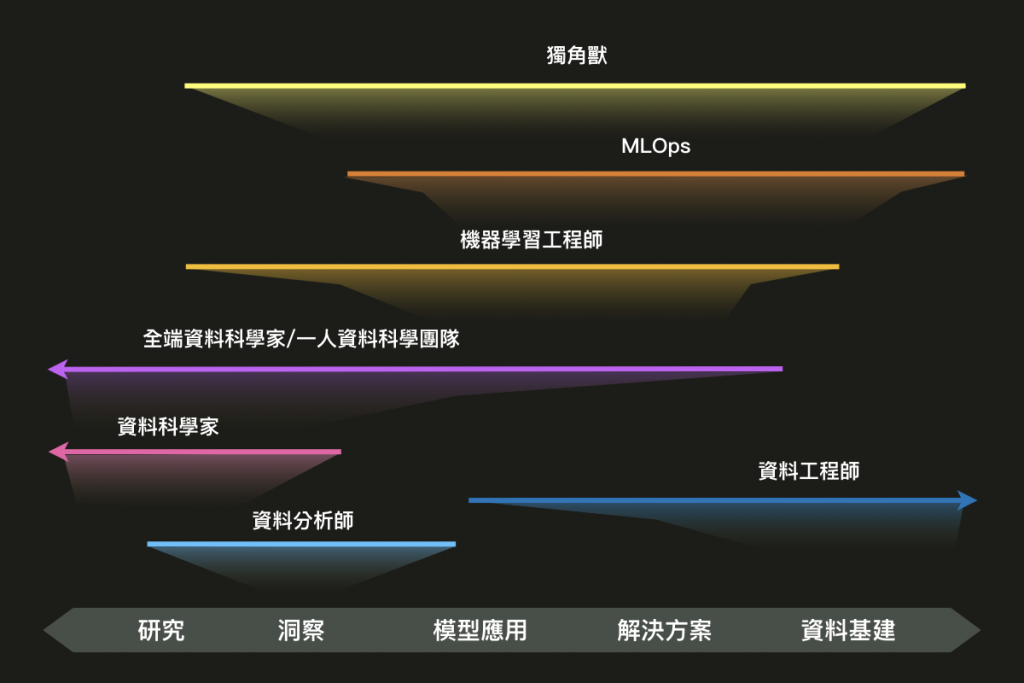
必須強調的是,這張圖只是幫助了解角色定位,並非比較高下,深度與廣度沒有一定的好壞,不同團隊在不同階段也會需要不同的角色,這是非常合理的。
這就是我目前所知道的部份,希望可以幫助更多人了解這些角色的概念。你有從裡面找到團隊缺乏的角色嗎?或是你認為其中某些角色跟你的認知不一樣?歡迎分享給我知道。