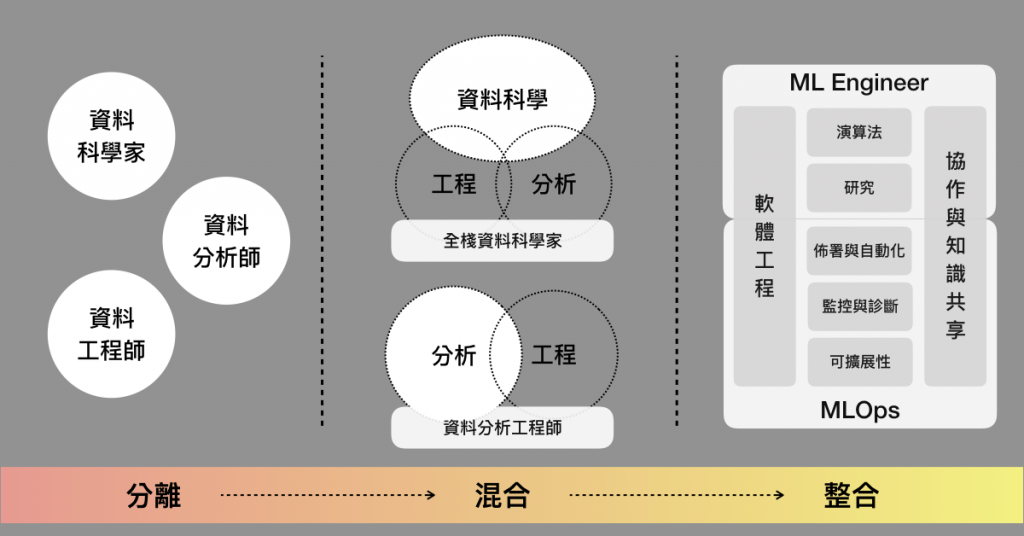
資料科學的職稱分類演進
「資料科學家到底做些什麼?」、「為什麼這間公司的科學家也要做資料工程?」、「資料清理是誰應該做的?」、「機器學習工程師跟資料工程師有差嗎?」、「資料分析師又跟他們差在哪?」
這些都是求職過程中,面試者很容易感到疑惑的地方,部分獵頭、recruiter 與用人主管也未必能回答地很清楚,所以常常碰到不同職缺名稱,工作內容差不多,或是明明一樣的職稱,在不同公司的工作內容差異卻很大的情況。
如果你正在這個領域找工作,或是正在做相關的招募,我想這篇的內容你可能會有些興趣。
三階段的演進
因為這是個還在發展中的領域,台灣的環境又更特別一點,軟體工程人才與生態並不像矽谷與其他國家那樣豐富,再加上對資料科學研究領域有興趣的人才非常多(比起工程多了不少),因此早期業界開出的職缺幾乎都是分離狀態(將科學家、工程師與分析師完全分開),雖然定義清楚,但很容易就出現混用的情形。
因此這幾年也逐漸看到出現了混合職稱,以及逐漸走向逐漸整合的職稱,似乎開始正視工程領域的重要性,這是蠻有趣的現象。
當然,這只是從我個人經驗中的觀察所做的歸納,或許每個人對於資料科學職缺分類演進的解讀也不同。而隨著時間過去,這些分類方式也會過時,所以我認為有幾個分類、名稱叫做什麼並不是那麼重要,而是在這些過程中的觀察,也歡迎跟我分享你的想法。
理想:分離職缺(Separated Positions)
這是很理想的狀況,三種定位很明確,工作有各自的切分領域,但真實世界卻很難獨立存在這樣的職稱。
資料科學家 Data Scientist
理想上,資料科學家的範疇包含:
- 根據產品需求設計實驗流程,找出最有可能改善模型的方法
- 研讀論文、推導邏輯與式子並證明自己的解法可行(或別人的方法不可行)
- 實作最新的論文到既有產品上
- 在一堆看似雜亂無章的資料中挖掘他們的價值,做出對公司有利的提案
資料工程師 Data Engineer
有兩種類型的資料工程師,一種是應用領域,另一種是著重在基礎建設,各有稍微差異,不過先讓我廣泛地稱他們都是資料工程師,工作範圍包括但不限於:
- 資料湖泊(data lake)、資料倉儲(data warehouse)與資料超市(data mart)
- 串接上面這些資料中心的管線(ETL / data pipeline)並自動化
- 資料清理(data cleansing)與資料治理(data governance)
- 資料平台(計算引擎、資料庫)的規模化
資料分析師 Data Analyst
以金融業最有代表性,當然所有需要資料分析報表協助決策的各行各業也都會有這個職缺,代表性的工作有:
- 使用統計分析,做報表(excel, google sheet)、使用 database(SQL)
- 應用商業與領域知識,找到洞察,並將故事說出來
- 使用前端視覺化工具,說服別人這個內容是有價值的
妥協:混合職缺(Hybrid Positions)
理想很豐滿,現實卻很骨感。想做純研究的人雖然很多,但研究一定伴隨著工程,於是企業的職缺開始出現一些混合工程的職稱。
全棧科學家(DS + DE/DA)
這是多數中小企業資料科學家的「真名」:既需要作研究,也要做上線的黑手工程,當然也少不了分析報表的活。
如果公司是新創,要將機器學習應用在產品上,那麼你可能為了要把模型放到產品上自動化,自己寫了很多程式。像是當個資料工程師處理 ETL/data pipeline,清理資料;或是後端伺服器工程師,寫些 API 與 server,有時候還要排除一些網路與硬體等基礎建設的問題。
雖然多數容易淪為工程打雜活,但也有部分公司有比較明確的系統分工,能夠擴展到全棧科學家。
參考:「全棧科學家」模式不適用的可能原因 - 科科寫寫
資料分析工程師(DA + DE)
這是某些產業可能會出現的情況,一個資料分析師會碰到工程面,包含接接水管、建立資料倉儲、甚至寫寫後端伺服器,都是有可能的。但因為是分析導向,而不是自動化的機器學習產品,工程活或許略少一點。
跟全棧科學家相似之處:有些時候可以累積多一點領域的實務經驗(甚至比資料科學家還多),也不可避免地會有比較黑手的部份,
跟全棧科學家的差別:這些產業可能不需要研究艱難的機器學習演算法,而是以分析商業需求與洞察為主,所以雖然也有點像全棧,但出發點變成 Analyst。
成熟:整合職缺(Integration Positions)
ML Engineer 與 MLOps 的出現
DS 與 DE 分離的最大問題就是多數資料科學家的思維並不能直接用在資料工程上,科學家可能也不想作工程師,而工程的需求通常又遠大於科學。

出處:Data engineers vs. data scientists - O’Reilly Media
機器學習工程師(ML Engineer)
於是開始出現了機器學習工程師,雖然他仍然負責機器學習相關的工作,但重點是那些「所有跟 production 有關的工程」,而非模型本身,這類工作不但需要工程實務經驗,也需要一些基本的學術知識,但我認為就如他的名字一樣,仍然是個工程師。

相較於統計與數學背景,機器學習工程師通常是從 CS 背景的軟體工程師或者資料工程師特化而來;但在台灣早期,念 CS 機器學習背景的本科生,頂著資料科學家的職稱,做機器學習工程師的事情,這種情況也是有的。
下圖是另一種三分的表示法,概念上並無太大差別,不過附上了很多細節說明,告訴你他認為的對應技能有哪些:

出處:Machine Learning Skills Pyramid V1.0
也就是說,並非只有資料工程師(金字塔下層)可以成為機器學習工程師,反過來從資料科學家(金字塔上層)也是有可能走向這條路(我自己比較像是後者)。
這個職稱的精神在於解決問題,是多數尚未成為科技巨擘的公司最需要的空缺,我自己的感受是使用這個名稱的公司有越來越多的趨勢,逐漸取代幾年前以資料科學家為主的狀態。
MLOps
大約在 2018 年,ParallelM 與微軟等公司開始提出 MLOps 這個概念,說穿了,他的內容大家都並不陌生,其實就是將平常機器學習產品需要的工程面全部集合起來,系統化地條列出來,包含但不限於:
- 佈署(deployment)與自動化(automation): 如何將模型放到線上供服務呼叫?如何將整個訓練過程自動化?
- 模型與預測的可重現性(Reproducibility of models and predictions):如何保留模型的版本?如何做版本控制?
- 診斷(Diagnostics):如何知道整個機器學習系統問題出在哪?
- 資料監管與遵守法規(Governance and regulatory compliance):如何管理雜亂無結構化的資料?如何遵守 GDPR?
- 可擴展性(Scalability):如何規模化、或平行訓練模型?
- 協作(Collaboration):如何讓領域知識與資料科學家的知識能夠共享?
我認為這個職缺的概念更實際了,雖然跟 ML Engineer 涵蓋的守備領域很接近,但這個名稱很直白的點出「就是要做營運」,並且將真正上線之後遇到的各種問題明確的指出來。
一個好的 DevOps 首先要是一個合格的 Developer,也要有維護、營運軟體產品的經驗,否則無法有效率根據軟體工程需求做自動化,就容易淪為單純手工活,並沒有太多幫助;MLOps 與它類似,要有部分 ML 知識能了解機器學習產品的需求,再加上營運軟體服務的經驗,這也是以往在做產品最耗費人力的地方。
小結:理想、妥協與成熟
回顧三個階段,DS/DE/DA 在早期描述了一個很美好的資料科學藍圖,我認為精神在於描繪出「理想」,把科學與工程完整分離,讓大家覺得人人有機會作研究,進入大科學時代。
再來是全棧資料科學家、資料分析工程師這些以研究、分析為主,工程為輔的職缺,我認為精神在於「妥協」:仍然是以科學為主,工程為輔,但不得不承認工程的重要性。
而接著的 ML Engineer 的精神在解決方案(Solution)、MLOps 的精神則是營運(Operation)。到這個階段,已經較少看到新創一窩蜂地開出資料科學家的職缺,或許代表這個領域已經逐漸成熟。
未來,這些職缺或許都會成為軟體工程師(Software Engineer)的一部分,就像其他的研究領域一樣,大部分都是工程師的工作,只有極少數研究單位在努力突破科技的界線。
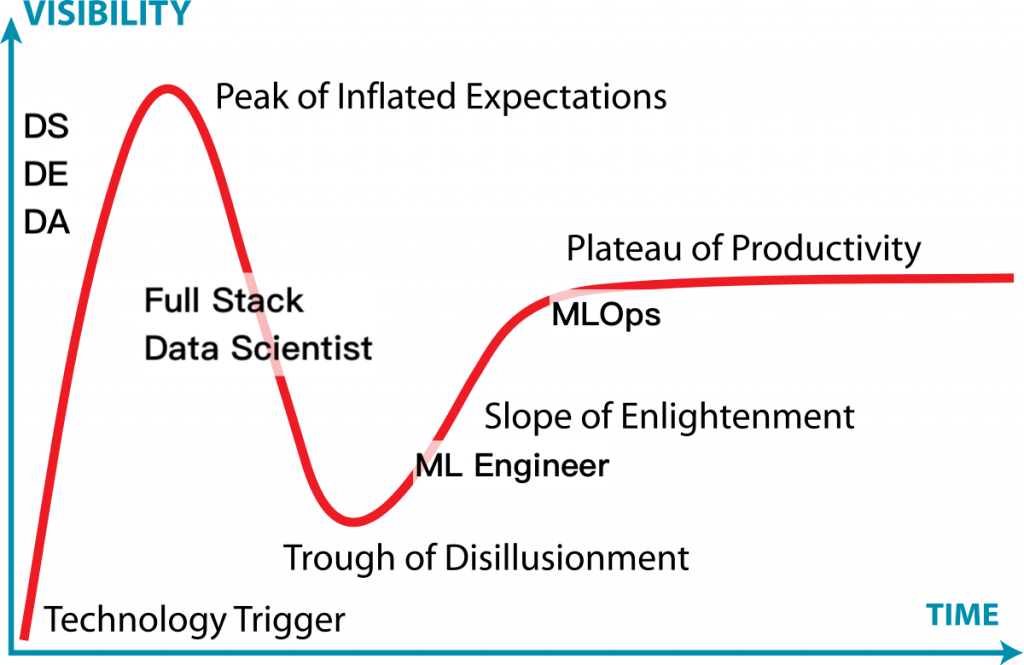
最後,我把技術成熟度曲線(Gartner Hype Cycle)標上對應的職缺名稱,打算幾年過後再回頭來看看,是否跟我現在想的一樣已經快到高原期了?還是其實沒那麼快?就留給時間證明。