
為何資料工程人才難以培養?

示意圖:被巨量資料開發的隕石砸到
這幾年我很常聽到快畢業的學生,或是剛踏入職場的新鮮人詢問,要如何培養資料工程的實務能力,像是:
我很希望自己有更好的資料工程(ETL/data pipeline)實務能力,但是在校內根本不可能有這種機會
或是聽到有人因為科學家的職缺並不多,而想要轉職成為工程師,但也不得其門而入:
目前大多是以如何成為 Data Scientist 的課程居多,既然 Data Engineer 缺的人比較多,為何市面上不多開一些這種課程?
我也曾經簡單在 PTT 回過一篇相關的文章,這次趁機會把更多細節說清楚。
以前學校也不太教前端或網頁技術,還是有很多人可以自學、或是透過線上課程、實體課程「出師」轉職成為工程師。
但在資料科學領域,為什麼要透過類似的方式轉職資料工程師就比較困難?除了學校有出現一些學程跟系所之外,沒有什麼線上跟實體課程來幫助想轉職的人嗎?雖然有,但多半著墨在工具與技術的使用上,而只會這些工具並無法輕易跨越成為資料工程師的鴻溝,我認為可以分別從學界與業界來看原因。
學界養成資料工程人才的困難點
軟體工程需要長時間開發以及多人合作,學校無法提供
追根究柢,資料工程也是軟體工程的一部分,雖然本科學生應該都修過軟體工程,但學校根本沒有對應的工作環境可以提供軟體工程的練習。
如同我之前在《先有軟體與數據文化,才有AI》寫的:
很多東西是只有在業界產品才能學到的,像是 ETL、軟體工程、特定領域資料的知識。並且很遺憾地,也無法速成
首先,學校的課程時間有限,扣掉學習知識的時間、其他課程重疊共享的時間,以及紙本作業與考試的時間,最多只有幾周留給程式實作與開發,所以作業專案都傾向用已知解決方法的問題、需求也相對固定,不會很常變更,很容易就限縮在一人單打獨鬥的範疇(scope),有些甚至還可以抄解答。
這是學校課程先天的限制。而沒有實際的產品生命週期(Life Time)、沒有長時間的專案管理(Project Management)與藍圖(Roadmap),學生就不需要維護程式碼以及考慮擴充性,也因為多半是兩三人,甚至一人專案,就沒有跨部門溝通與撰寫註解、文件、傳遞知識的需求。
這裡並非在批評學校的教學方式不好,反而我認為在核心基礎課程當中,不牽涉太多實務經驗也是好的;台灣學校的弱項是薪酬比較難吸引有經驗的業界人士回去教學,因此相對應用的課程就比較少。
資料系統的狀態管理經驗難以在學界取得
上面是軟體工程都有的問題,而資料工程更需要業界的實務經驗才能取得。
舉例來說,資料工程最常做的一件事情就是建立 pipeline,而一個複雜的 ETL pipeline 可能不具備「冪等性」(特別是在 data sink 階段),也就是說,執行一次 ETL 跟執行第二次可能會得到不同的結果(比如把到目前為止新增的使用者倒入資料庫,每次執行都會比上一次更多)。
就算 ETL 的某部分具備冪等性,但在兩次操作之間,資料庫狀態卻可能因為別的原因被改變了,也就是說有額外的干擾進入了系統,這時候就不只是一個 ETL 的問題,更牽涉到資料監管(data governance)以及資料沿襲(data lineage)等課題。
再來,資料的版本能追蹤嗎?能還原嗎?不同資料庫之間的同步要如何確保?如果兩個系統的資料不一致要怎麼辦?這些有狀態的資料在不同的專案中流動,讓整個系統像一坨義大利麵,該如何理解與維護?
然而在大學多數都是無資料庫的專案,或者是接近一個 snapshot 的資料庫存檔;在研究所,拿到夠完整的資料集(dataset)已經是極限了。要模擬出真實的軟體工程,甚至是大流量的線上應用服務,基本上是不可能的。
資料工程需要大量流動的資料,如果只能拿到死的 dataset,即使數量級夠大,很多實務上的問題也無法練習,這就是為什麼雖然有 Kaggle 這類平台能給你資料科學的經驗,卻少見有平台能給你資料工程經驗的原因。
業界養成資料工程人才的困難
除了學界,業界要培養資料工程人才也不容易。
既然資料工程的技能養成難以在學界完成,自然就幾乎都是以在職訓練(On-the-job Training,換個說法就是邊作邊學)為主,但業界也未必有能力訓練。
隱私資料只掌握在大企業手上
用隱私資料來賺錢畢竟是大企業的命脈,所以這是一個相對封閉的領域,不能公開的原因有很多,其中之一當然是賺錢機密,再者則是企業對於客戶資料的安全性有顧慮,就算做了去識別化,也難保不會有隱私上的疑慮,對大企業來說,公開分享隱私資料基本上有百害而無一利。
程式可以自己在家練兵,任何人只要有技術能力就可以自己架設網站、寫 app;但資料科學若沒有大量資料就沒有辦法訓練模型,同樣地,資料工程若沒有大量資料,就沒有辦法累積實戰經驗。
程式當然還是會跑得動,但就算我們技術再強,都無法用臉書的資料訓練模型、處理臉書量級的資料。既然碰不到實際的資料,因此那些沒有足夠資料的中小企業,在人才培育上也就相對處於弱勢。
「沒空」處理工程問題
沒有資料可能是一個問題,但有資料也未必就很容易培養人才。因此雖然資料工程重要,但企業內部卻不一定會讓員工處理真正重要的資料工程問題。
我在《為什麼資料科學「曾經」比資料工程流行?》提到新創的困境:
反之,將系統模組化、泛用化的工程師,在這段時間中就相對式微:畢竟產品都還沒有穩定賣出,今天做好的雛形可能明天客戶就不要了,系統在模組化、維護、擴展性的需求都不高,就算有這樣的需求,也是求快速暫時解決,往下一個產品功能邁進。
雖然最後粗暴地總結為「沒空」,但總之就是迫於現實因素或其他原因,沒辦法花太多資源在做資料工程。
雇用錯置,企業不知道自己遇到的是工程問題
雇用錯置問題(Hiring Out-Of-Order Problem)是從 @rchang 學來的名詞,意指在「資料科學需求金字塔」中,雇主傾向雇用那些專精在資料科學,但卻對資料工程沒什麼經驗的人。
One of the recipes for disaster is for startups to hire its first data contributor as someone who only specialized in modeling but have little or no experience in building the foundational layers that is the pre-requisite of everything else (I called this “The Hiring Out-of-Order Problem”).
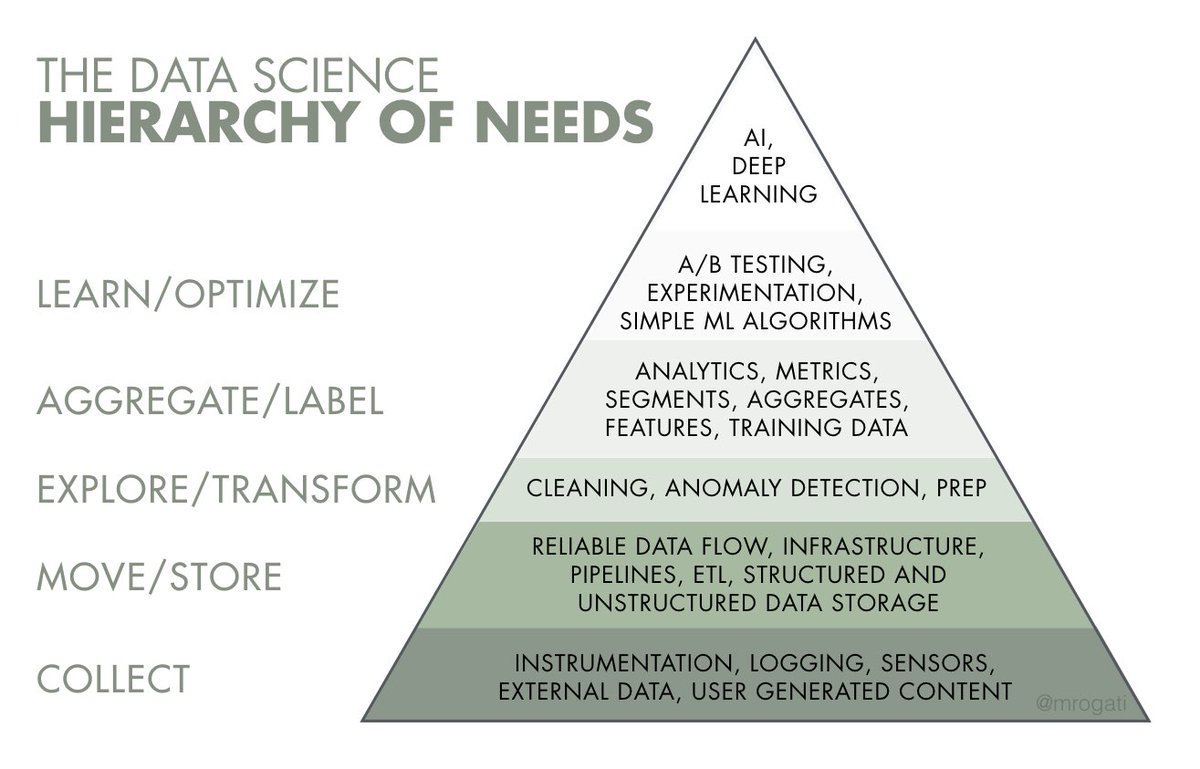
非常多的雇用錯置,發生在各公司裡面,比如很常聽到的「學了機器學習以為工作是建模,結果上班整天都在清資料」。
如果比喻成做料理的話,在客人眼中只有廚師做菜的時候是被看見的,但在那之前摘水果(資料收集)、清洗食材(資料清理)、搬運食材(資料流)、儲存(資料庫)、毒物檢驗(異常資料偵測)、中間產物(預處理)卻很容易被忽略,以致於請了很多廚師,都在做不是廚師該做的工作。
這會導致廚師料理的效率變差,而且因為沒人看到,所以每個廚師都想辦法盡量偷吃步快點拿到食材,前面的工程步驟也很難被提出來系統化改進。
企業習慣把資料工程外包
而另一種情況則是歷史較悠久的大企業,雖然有很多資料,但可能長年利用外包顧問的方案,內部已經有一套依賴這個方案的作法,注重的是穩定性與維運,很難讓員工有自己下去處理的機會,即使有新的需求也是以現有的方案擴充為主。
逐漸改善的契機
台灣傳統產業(電商、金融)的需求多半落在商業分析,而新創又較少有巨量資料工程的需求,因此距離台灣企業能培養出資料工程人才還有一大堆距離要走,但至少台灣這幾年從事相關行業的人慢慢增加、也逐漸與世界接軌、重視資料工程。
以上提到的問題,一部分原因是對資料工程的經驗與理解不夠,幸好這領域也慢慢地比較成熟,不但有很多框架跟知識被建立起來,國外很多文章跟著作也都已經有了比較系統性的討論,隨著越來越多人理解之後,我相信還是會逐漸改善,這也是我撰文的目的之一。
沒有實務經驗,該如何踏上資料工程師之路?
這一兩年不少新鮮人或剛入職場一兩年的讀者,問我的問題多半是「我是 data analyst,想改做 engineer 增加競爭力該怎麼做」、「我是 ML researcher,想踏入 data engineer 領域該怎麼做」
甚至有人擔心「只做模型都不碰工程會不會沒有競爭力」
歸納類似這樣的職涯移動之後,我猜測原因可能包含:
- Data science 的線上課程跟競賽資源非常豐富,反觀 Data Engineering 則較少
- 科技巨擘做了許多像是 AutoML 的產品,降低企業導入 AI 的門檻
- 臺灣無法提供太多研究工作職缺,主要還是缺有實際經驗的軟體工程師
對於剛畢業的新鮮人,我很樂意撥出一點時間回答問題,不過長久來看,或許需要一個有機體,可以自主地發起討論並成長,或許未來就不會受限於我的經驗能力與時間,而我也可以從中學習到更多。
因此我創了一個 ? 資料森友會 TG 群組,如果你是:
- 剛畢業想加入這個領域的新鮮人
- 考慮轉職到這個領域的職場員工
- 有相關經驗(資料科學家/工程師/分析師)願意分享的職場人士
- 想知道業界資料科學/工程在做什麼的人
並且有興趣討論資料科學與工程的求職、轉職、職缺、職場經驗分享等話題,都歡迎加入
初期只能在我自己能力與經驗範圍內參與討論,期望未來有更多人進來互相討論分享。